Zasadniczym zadaniem importu specjalnego jest zmiana formatu danych wejściowych tak, aby odpowiadały wymogom programu importującego dane. Podczas importu mogą ulec zmianie wszystkie lub tylko cześć atrybutów danych, m.in.:
•Kolejność danych
•Wartość poszczególnych danych
•Sposób kodowania polskich znaków
•Relacje pomiędzy danymi
Ponadto:
Część danych (nadmiarowych) może zostać odrzucona
Brakujące dane mogą zostać odtworzone z innych danych lub uzupełnione wartościami domyślnymi
Wszystkie te operacje są zdefiniowane w szablonie importu specjalnego lub w procedurach wbudowanych kontroli poprawności.
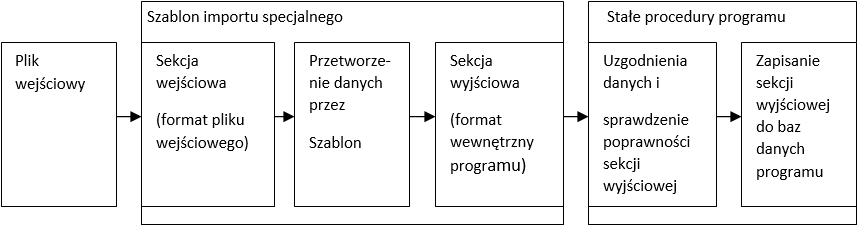
Dane wejściowe są przetwarzane cyklicznie w następujących etapach
•czytana jest jedna sekcja z danych wejściowych
•wczytana sekcja (sekcja wejściowa) jest przetwarzana przez szablon do postaci wymaganej przez program i zapisywana do sekcji wyjściowej
•program importujący dokonuje wszystkich potrzebnych uzgodnień danych i sprawdza poprawność sekcji wyjściowej
•dane są zapisywane do baz danych programu
Powyższy ciąg operacji wykonywany jest dla każdej sekcji w danych wejściowych.
Proces wczytywania danych ilustruje poniższy rysunek:
Proces importu danych